Prompt Tuning for Sequence Classification
In my previous blog post Zero-Shot Text Classification with pretrained LLM, I used Qwen2.5-0.5B-Instruct for sentiment analysis without any training. With some tweet on the prompts, we can see an improvement of accuracy from 77.5% to 82.5%. We might be able to squeeze the performance even more with prompt engineering, but it is inefficient as most of the time we don't know why one word is better than another in the prompts. Instead of prompt engineering, we can do prompt tuning with some labelled data, which is one of the parameter-efficent ways to fine tune a LLM model. Its main idea is to prepend some tunable tokens to some task specific prompt while freezing the LLM model. We then train the embeddings of the prepended tokens on the labelled data so that the learned tokens can align the task specific prompt better to the task.
from datasets import load_dataset
from peft import PromptTuningConfig, get_peft_model, PromptTuningInit, TaskType
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import Trainer, TrainingArguments
import torch
from datasets.utils.logging import disable_progress_bar
disable_progress_bar()
0. Prompt Tuning
Prompt tuning prepends some virtual tokens to the actual prompt tokens. The virtual tokens come with trainable embeddings that have the same dimension as the ones from the LLM's embeddings. The concatenation of embeddings from both virtual tokens and prompt tokens are then fed into the LLM.
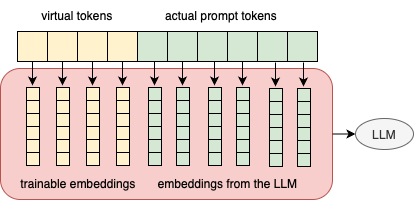
Most LLMs in 🤗 Transformers accept two kinds of inputs: input_idsor inputs_embeds. Usually we will tokenize texts into token ids and feed the ids to the models via input_ids. But for prompt tuning, we need to use inputs_embeds. The reason is obvious - the original models don't have any inforamtion about the virtual tokens. Using inputs_embeds posts a challenge for batch inference for our example use case here: the sequence classification models rely on the input_ids to detect the last non padding tokens and use their embeddings to do scoring/prediction. If we use inputs_embeds, it makes it harder to detect the last non padding tokens. We will use Qwen2ForSequenceClassification later in this blog. The current implementation of the model use the last tokens for the classifiation task when inputs_embeds is used.
If we have only one prompt/text as input, then there is no issue. However, if we want batch inference, we will have to do padding if the input prompts are not of the same length. There are two ways to pad the batch, left or right.
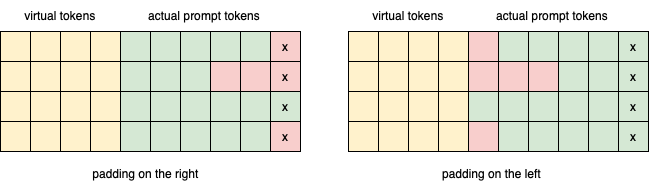
The above image shows the right and left padding of a batch in prompt tuning. The red boxes are the padding tokens. The tokens marked with "x" are the ones used in the classification task in the current implementation when inputs_embeds is used. It is clear from the iamge that we should pad on the left so that the correct tokens are used in the classification.
1. Data Preparation
I will use the same financial sentiment analysis data as in my previous posts, so that we can compare prompt tuning to prompt engineering.
ds = load_dataset("vumichien/financial-sentiment")
print(ds)
DatasetDict({
train: Dataset({
features: ['text', 'label_experts'],
num_rows: 1811
})
valid: Dataset({
features: ['text', 'label_experts'],
num_rows: 453
})
})
labels = ["positive", "negative", "neutral"]
label2id = dict(zip(labels, range(3)))
id2label = dict(zip(range(3), labels))
We will prepare the dataset in our base prompt:
What is the sentiment of the following text related to finance?
negative, neutral or positive: {text}
Give your answer in one word.
The prompt will have 77.5% in accuracy on the validation set.
ATTENTION: we need to pad on the left to correctly use the last tokens in the prompt for classification.
model_path = "Qwen/Qwen2.5-0.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(
model_path,
padding_side="left",
)
user_prompt_template = """What is the sentiment of the following text related to finance?
negative, neutral or positive: {text}
Give your answer in one word."""
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": user_prompt_template}
]
prompt_template = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
print(prompt_template)
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
What is the sentiment of the following text related to finance?
negative, neutral or positive: {text}
Give your answer in one word.<|im_end|>
<|im_start|>assistant
def get_prompt(example):
prompt = prompt_template.format(text=example["text"])
return {"prompt": prompt}
ds = ds.map(get_prompt)
print(ds)
DatasetDict({
train: Dataset({
features: ['text', 'label_experts', 'prompt'],
num_rows: 1811
})
valid: Dataset({
features: ['text', 'label_experts', 'prompt'],
num_rows: 453
})
})
2. Setup Model
We load the LLM as a classifier. We use the corresponding token weights for the labels positive, negative and neutral to initialize the score weight. Usually we will get those token weights from the LM head. However, for Qwen2.5 family, its tie_word_embeddings is true, meaning that the LM head reuses the weights from the embedding layer. We will pull the weights from the embedding layer as well.
model = AutoModelForSequenceClassification.from_pretrained(
model_path,
num_labels=len(labels),
id2label=id2label,
label2id=label2id,
torch_dtype="float32",
device_map="auto"
)
# set the pad token
model.config.pad_token = tokenizer.pad_token
model.config.pad_token_id = tokenizer.pad_token_id
# initialize the score layer for the classifier
labels_token_ids = [
tokenizer.encode(label)[0]
for label in labels
]
with torch.no_grad():
score_weight = model.model.embed_tokens.weight[labels_token_ids]
model.score.weight.copy_(score_weight)
model.model.embed_tokens.weight[tokenizer.pad_token_id] = 0.0
Sliding Window Attention is enabled but not implemented for `sdpa`; unexpected results may be encountered. Some weights of Qwen2ForSequenceClassification were not initialized from the model checkpoint at Qwen/Qwen2.5-0.5B-Instruct and are newly initialized: ['score.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Now let's evaluate the model on the validation set to confirm that the model is correctly initialized. The accuracy should be around 77.5% with this prompt.
def eval_model_on_accuracy(model, tokenizer, dataset, batch_size=32):
"""Evaluate the model's accuracy on the dataset.
The dataset is assumed to have `prompt` and `label_experts`.
"""
predicted_labels = []
prompts = dataset["prompt"]
for batch_begin in range(0, len(prompts), batch_size):
batch_end = batch_begin + batch_size
batch_texts = prompts[batch_begin: batch_end]
# tokenize batch of texts
batch_inputs = tokenizer(
batch_texts,
padding=True,
return_tensors="pt",
).to(model.device)
# scoring
with torch.no_grad():
batch_outputs = model(**batch_inputs)
# get the last predicted tokens
predicted_ids = batch_outputs.logits.argmax(-1)
for pid in predicted_ids:
predicted_labels.append(labels[pid])
correct = 0
for predicted, truth in zip(predicted_labels, dataset["label_experts"]):
correct += predicted == truth
accuracy = correct / len(dataset)
print(f"Accuracy: {accuracy:.2%}")
eval_model_on_accuracy(model, tokenizer, ds["valid"])
Accuracy: 78.59%
Yep, we got a well-initialized model. It is a bit higher in accuracy than expected because we use "float32" instead of "bloat16".
3. PEFT model for Prompt Tuning
The most important hyperparameter for prompt tuning is the number of virtual tokens num_virtual_tokens that got prepended to the prompt. There are multiple ways we can initialize the weights of the tokens:
1. randomly,
2. use the embeddings of the labels positive, negative and neutral,
3. use the embeddings of the task description.
Here, I will take the 3rd approach.
task_desc = "Classify the sentiment of the financial statement into positive, negative and neutral."
peft_config = PromptTuningConfig(
task_type=TaskType.SEQ_CLS,
prompt_tuning_init=PromptTuningInit.TEXT,
num_virtual_tokens=20,
prompt_tuning_init_text=task_desc,
tokenizer_name_or_path=model_path,
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()
trainable params: 20,608 || all params: 494,056,064 || trainable%: 0.0042
Let's take a look at the initial accuracy of the peft_model. It is most likely slightly worse than the original model as it has not yet been trained.
eval_model_on_accuracy(peft_model, tokenizer, ds["valid"])
Qwen2ForSequenceClassification will not detect padding tokens in `inputs_embeds`. Results may be unexpected if using padding tokens in conjunction with `inputs_embeds.`
Accuracy: 75.50%
4. Training
We will tokenize the training dataset into something the model is ready to intake. We will further split the training dataset into two parts, one for actual training and other for validation in the training process.
def tokenize_dataset(example):
"""Tokenize the examples."""
prompt = example["prompt"]
inputs = tokenizer(prompt, truncation=False)
inputs["labels"] = label2id[example["label_experts"]]
return inputs
# tokenize the prompt and labels
tokenized_train = ds["train"].map(
tokenize_dataset,
remove_columns=ds["train"].column_names
)
# split the train further into train_train, train_valid for training
tokenized_train = tokenized_train.train_test_split(test_size=0.25)
tokenized_train
DatasetDict({
train: Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 1358
})
test: Dataset({
features: ['input_ids', 'attention_mask', 'labels'],
num_rows: 453
})
})
We are finally ready to do prompt tuning!
BATCH_SIZE = 8
training_arguments = TrainingArguments(
output_dir="data/prompt-tuning",
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
num_train_epochs=10,
learning_rate=1e-5,
weight_decay=0.01,
eval_strategy="epoch",
save_strategy="epoch",
logging_strategy="epoch",
load_best_model_at_end=True,
)
trainer = Trainer(
model=peft_model,
processing_class=tokenizer,
args=training_arguments,
train_dataset=tokenized_train["train"],
eval_dataset=tokenized_train["test"]
)
trainer.train()
None
No label_names provided for model class `PeftModelForSequenceClassification`. Since `PeftModel` hides base models input arguments, if label_names is not given, label_names can't be set automatically within `Trainer`. Note that empty label_names list will be used instead.
<IPython.core.display.HTML object>
| Epoch | Training Loss | Validation Loss |
|---|---|---|
| 1 | 0.467900 | 0.398714 |
| 2 | 0.337400 | 0.314317 |
| 3 | 0.282200 | 0.272602 |
| 4 | 0.250900 | 0.246164 |
| 5 | 0.238500 | 0.231969 |
| 6 | 0.230400 | 0.222497 |
| 7 | 0.221400 | 0.222217 |
| 8 | 0.217900 | 0.216793 |
| 9 | 0.211900 | 0.214810 |
| 10 | 0.211800 | 0.213523 |
I did 10 epochs only. But it seems pretty good when looking at the training vs validation loss. We also see a big jump in accuracy as well:
eval_model_on_accuracy(peft_model, tokenizer, ds["valid"])
Accuracy: 93.16%With only 0.0042% of the original parameters, we are only to improve the accuracy to 93.2% from 78.5% - a 15% absolute gain! I highly recommend prompt tuning over prompt engineering if you have some labelled data.
