LLM Tool Calling
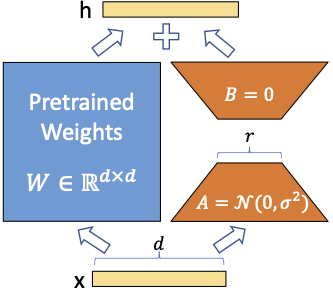
I recently tried to update my movie page but failed - the package cinemagoer could not fetch all the needed information from IMDb. I decided to try LLM instead of a rule based engine to extract movie information. It works and works pretty well with tool calling for a structured output. I am going to document my understanding of tool calling, what it is for, and how to use it for structured output.
Quick note: Codes are tailored to Qwen/Qwen3-4B-Instruct-2507 and mlx_lm. They might need adjustment with other models and frameworks.