Clustering Weibo Tags
I started a projected last October to collect Weibo's top search data (微博热搜榜) hourly. Together with the keywords or tags (关键词), most recent related weibos (or tweets) are collected as well. The result is save to a JSON file, with the format explained in this page.
In this post, I would like to explore this data set and try to cluster tags. To be more precise, multiple tags can be used to refer to a same event, and these different tags are related and even share the same meaning. The task is to group similar tags together based on the data collected.
The Graph of Tags
The idea shown in this post to cluster tags is to build a graph of tags according to their co-occurance, and treat each connected component as a cluster of tags. In this graph, tags are vertices and the weight of an edge connecting two tags are the number of co-occurances.
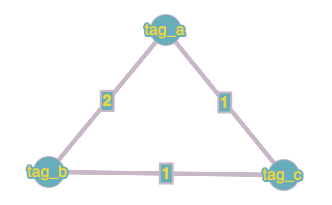
For example, if we have two weibos:
weibo1: #tag_a# #tag_b# blah blah blah ...
weibo2: #tag_a# #tag_b# #tag_c# blah blah blah ...
In weibo1, we see two tags tag_a and tag_b, and in weibo2, we see three tags tag_a, tag_b, and tag_c. From these two weibos, we have a graph of 3 vertices, tag_a, tag_b and tag_c. The edge connecting tag_a and tag_b has weight 2, becuase the pair (tag_a, tag_b) appears in two weibos. Similarly, the two edges conecting tag_c to tag_a and tag_b both have weight 1.
In order to build the graph, we need to be able to extract tags out of weibos.
def find_tags(content):
tags = set()
p = -1
for i, c in enumerate(content):
if c != "#":
continue
if p == -1:
p = i
else:
tag = content[p + 1: i].strip()
if not tag:
p = i
else:
tags.add(tag)
p = -1
return list(tags)
We can try the function find_tags on our previous examples.
weibo1 = "#tag_a# #tag_b# blah blah blah ..."
weibo2 = "#tag_a# #tag_b# #tag_c# blah blah blah ..."
print(f"Tags in weibo1: {find_tags(weibo1)}")
print(f"Tags in weibo2: {find_tags(weibo2)}")
Tags in weibo1: ['tag_b', 'tag_a'] Tags in weibo2: ['tag_c', 'tag_b', 'tag_a']
Now suppose we have a list of data, each element in the list representing a fetched JSON file. A sample fetched JSON file can be found here: sample. Let's write a function to build a graph out of this list of data.
import collections
def build_graph(data, top=20):
tags = set()
for entry in data:
if entry is None:
continue
for topic in entry[:top]:
tags.add(topic["tag"].strip())
graph = collections.Counter()
for entry in data:
if entry is None:
continue
for topic in entry[:top]:
for w in topic["weibo"]:
nodes = list(filter(
lambda t: t in tags, find_tags(w["content"])))
for u in nodes:
for v in nodes:
if u == v:
continue
graph[u, v] += 1
return list(tags), graph
Note that there could be tags that are not presented in the hot searches, but appear in some weibos. Those tags are ignored in the graph. We next build a graph of tags using the sameple JSON file and the build_graph.
import json
import requests
sample_url = "https://wormtooth.com/files/2019101510.json"
page = requests.get(sample_url)
data = [json.loads(page.content)]
tags, graph = build_graph(data)
print(f"There are {len(tags)} tags in the sample JSON file.")
There are 20 tags in the sample JSON file.
seen = set()
edges = []
for k, v in graph.items():
if k[0] not in tags or k[1] not in tags:
continue
if k in seen or (k[1], k[0]) in seen:
continue
seen.add(k)
edges.append((k, v))
edges.sort(key=lambda x: -x[1])
print(f"Edges with highest heights:\n{edges[:4]}")
print()
print(f"Edges with lowest heights:\n{edges[-4:]}")
Edges with highest heights:
[(('魏晨成功求婚', '魏晨女友'), 26), (('宝马姐就怒怼维权车主致歉', '热依扎工作室声明'), 4), (('国考报名', '雪莉确认死亡'), 2), (('输错药致患儿死亡2护士被辞退', '宝马姐就怒怼维权车主致歉'), 2)]
Edges with lowest heights:
[(('为什么不让宁王上', 'iG输了'), 1), (('詹姆斯 让我们先发声不公平', '宋茜'), 1), (('魏晨成功求婚', '40年前就曾发现火星上有生命痕迹'), 1), (('胖子和瘦子互换饮食', '涠洲岛失联少女早晨监控'), 1)]
The Connected Components
In a undirected graph, two vertices are connected if there is an edge connecting the two vertices. In our graph of tags, two tags are connected if they appear at the same time in a weibo. But co-occurance at the same weibo does not necessarily imply they are related. We are going to use a number thredshold, and consider two tags are connected only if they appear at the same time in at least thredshold different weibos.
def connected_components(nodes, graph, threshold=1):
seen = set()
def bfs(x):
stack= [x]
seen.add(x)
i = 0
while i < len(stack):
s = stack[i]
for t in nodes:
if graph[s, t] >= threshold and t not in seen:
stack.append(t)
seen.add(t)
i += 1
return stack
comps = []
for node in nodes:
if node not in seen:
comps.append(bfs(node))
comps.sort(key=lambda x: -len(x))
return comps
By default, we set threshold to 1, using the connectness for the undirected graph. We should adjust the threshold according to the amount of data collected.
clusters = [None] * 7
print(f"There are {len(tags)} tags.\n")
for t in range(1, 7):
clusters[t] = connected_components(tags, graph, threshold=t)
print(f"There are {len(clusters[t])} clusters using threshold={t}")
print(f"Largest components has {len(clusters[t][0])} tags\n")
There are 20 tags. There are 6 clusters using threshold=1 Largest components has 11 tags There are 13 clusters using threshold=2 Largest components has 6 tags There are 18 clusters using threshold=3 Largest components has 2 tags There are 18 clusters using threshold=4 Largest components has 2 tags There are 19 clusters using threshold=5 Largest components has 2 tags There are 19 clusters using threshold=6 Largest components has 2 tags
The large the threshold is, the more clusters we have. To an extreme, if the threshold is bigger than the weights of any edges, each tag will be its own cluster. We don't want the threshold to be too small, because in this case, unrelated tags are grouped together. We don't want it to be too big neither, in which case related tags get separated. Thus, threshold is a parameter in this method. Since we don't have labelled data, we can now only manually tune this parameter.
for t in range(2, 5):
print(f"With thredshold={t}, the largest component is\n{clusters[t][0]}\n")
With thredshold=2, the largest component is ['李心草家属拒绝一切调解', '热依扎工作室声明', '警方通报李心草事件调查情况', '涠洲岛失联少女早晨监控', '宝马姐就怒怼维权车主致歉', '输错药致患儿死亡2护士被辞退'] With thredshold=3, the largest component is ['宝马姐就怒怼维权车主致歉', '热依扎工作室声明'] With thredshold=4, the largest component is ['宝马姐就怒怼维权车主致歉', '热依扎工作室声明']
In this particular dataset, threshold = 3 works the best. However, in this dataset, there is only one data point, corresponding to one fetched JSON at a particular hour. Naturally, we need to increase the threshold as we include more data.
Results
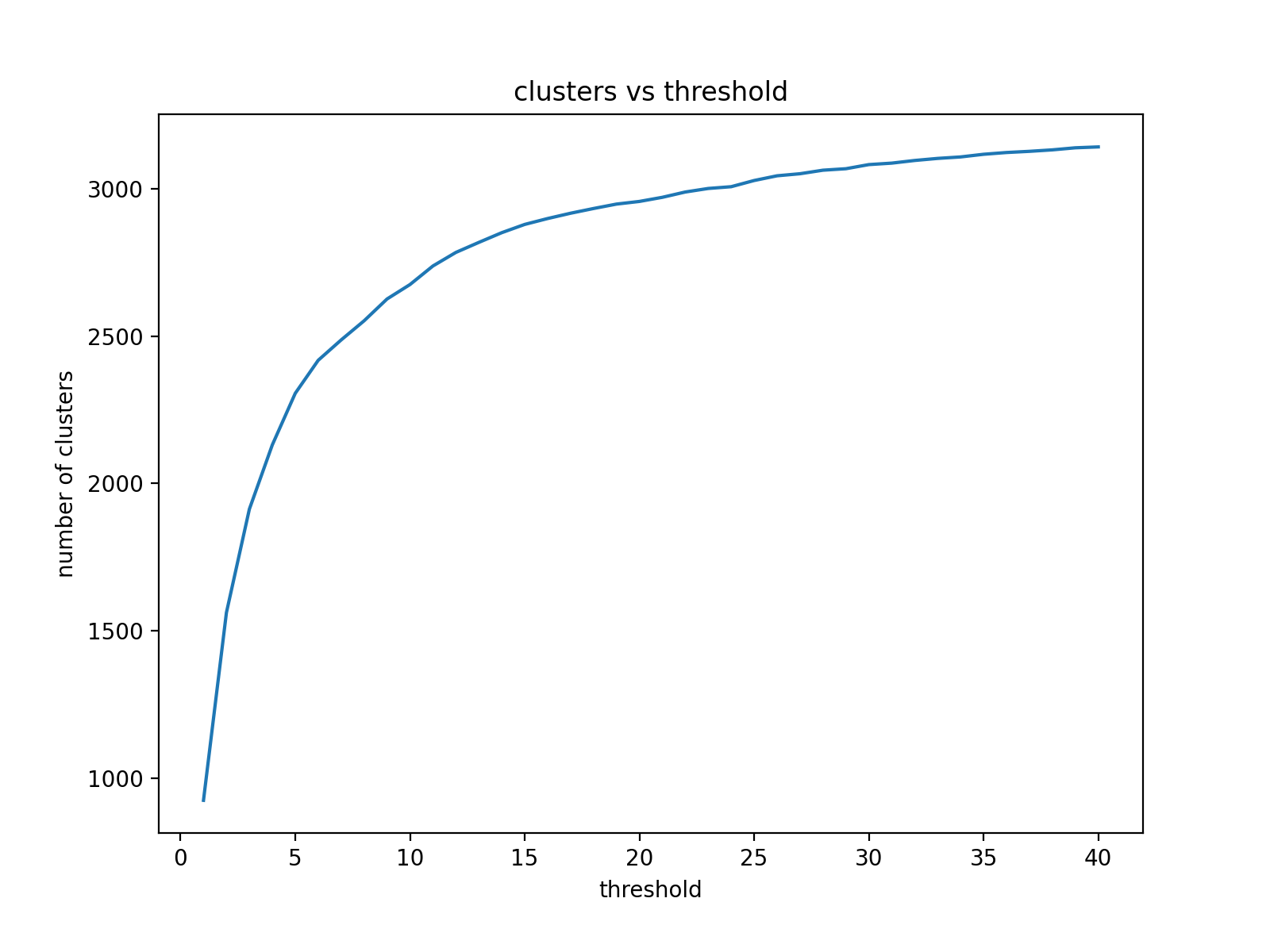
If we take all data from November, 2020, we would have 720 data points, as we have 720 hours in November. There are 3274 distinct tags if we consider only top 20 tags per hour. It turns out that with a month's data, threshold works well around 20. The largest 5 components using threshold=20 for November, 2020 are:
['美国大选烧钱创纪录', '特朗普发推要求停止计票', '内华达州的6张选票', '美国大选', '小红书崩了', '别再说自己是打工人', '特朗普将要求威斯康星州重新计票', '拜登在宾州反超特朗普', '美国大选选举日投票正式开始', '拜登', '梅拉尼娅建议特朗普接受失败', '拜登率先获得270张选举人票', '拜登赢得威斯康星州', '特朗普称拒绝接受将采取法律行动', '宾夕法尼亚州或将重新计票', '拜登向全国发表讲话', '外交部向拜登和哈里斯表示祝贺', '拜登称首要任务是控制疫情', '特朗普团队计票诉讼被两州驳回', '特朗普竞选团队在宾夕法尼亚州提起诉讼', '美大选当天移居加拿大搜索量暴增', '佐治亚州将重新计票', '美国同时出现抗议示威和上街庆祝', '特朗普团队在内华达州诉讼被驳回', '特朗普', '特朗普团队选举诉讼在多州被驳回', '拜登获306张选举人票特朗普获232张', '特朗普团队正募集6000万美元用于诉讼', '拜登在佐治亚州反超特朗普', '多家美媒掐断特朗普讲话直播', '拜登拿下关键摇摆州密歇根州', '白宫方面表示特朗普未准备败选演说', '谭德塞称期待与拜登团队合作', '特朗普金色头发变得花白', '拜登竟称美日安保条约适用钓鱼岛', '特朗普11亿美元债务表', '菅义伟与拜登进行首次通话']
['马苏 这几年摊上一些乱七八糟的事', '演员请就位', '郭敬明被尔冬升怼哭', '郭敬明版画皮的画面质感', '王楚然好适合南湘', '丁程鑫稚嫩妩媚感', '演员请就位版小时代好像小品', '尔冬升离场', '黄奕马苏倪虹洁把票让给张月', '郭敬明再给何昶希S卡', '赵薇导的剧场太好看了', '任敏哭着说压力好大太可爱了', '辣目洋子版顾里', '董思怡 好一个捧哏']
['萧胡辇怀孕', '燕云台', '萧燕燕儿子被下毒', '萧燕燕封后', '萧燕燕当太后', '萧家两姐妹大婚', '萧家三姐妹帮萧思温找凶手', '萧燕燕大婚', '燕云台大结局', '萧燕燕韩德让私奔', '韩德让辞职', '棋魂大结局', '棋魂', '日本网友对棋魂的反馈']
['狼殿下', '王大陆演技', '肖战疾冲', '李沁 我可是勇敢的马摘星', '那些年为肖战挡刀的女孩', '狼殿下台词又土又好笑', '狼殿下开播', '狼殿下弹幕', '狼殿下全集上线', '肖战李沁吻戏', '李沁演的马摘星', '王大陆蹭了李沁鼻子瞬间打了高光']
['丁真的字里有珍珠的影子', '全国各地都在邀请丁真', '丁真说不要再p了', '西藏日报 丁真我们在西藏等你', '四川为了丁真有多努力', '山东请求加入大乱斗', '怪不得四川观察总观察丁真', '黄子韬要去四川找丁真', '四川日报 玩够早点回家', '西藏拥有了躺赢的快乐', '丁真最想去的地方是拉萨']
The result is pretty good. It successfully groups all election-realted tags together, and separates topics for different TV series as well.
Here is a figure for number of clusters vs threshold. Recall that there are 3274 tags in consideration.